AI-Powered Image Selection: Automated Culling for Portrait Photography
View the Project Notebook · Google Generative AI Intensive 2025 Capstone Submission

Output Results of Generative AI Image Culling Process.
This project aims to automate and streamline the Image Culling process of professional portrait photographers by leveraging Generative AI —more specifically, Gemini Flash 2.0. I developed a system within a Kaggle Notebook that takes a collection of untouched portrait photographs as input and outputs a recommended selection of the top K unique (non-redundant) images based on predefined quality criteria that includes Lighting, Clarity, and the Subject.
Tech Tools
Python
Gemini Flash 2.0
NumPy
Pandas
JSON
PIL
Markdown
Scikit-learn
Prerequisites
Problem Statement
Image Culling is the critical process of sifting through numerous raw photographs to select the most promising images for post-production editing and refinement, presenting a significant bottleneck in a photographer's workflow. During a photoshoot, hundreds and even thousands of images are produced. Going through these image sets demands a substantial investment of a photographer's time and focused energy. This manual process diverts valuable hours away from other important aspects of a photographer's business which also includes shooting, editing, client communication, marketing, and much more. Generative AI plays a significant role in being able to speed up this process, increase efficiency and productivity, improve accuracy in identifying high-quality images, and enhancing client satisfaction.
Project Roadmap
This project will be executed through the following stages:
- Develop a proof of concept for an Image Culling System that processes a batch of portrait images
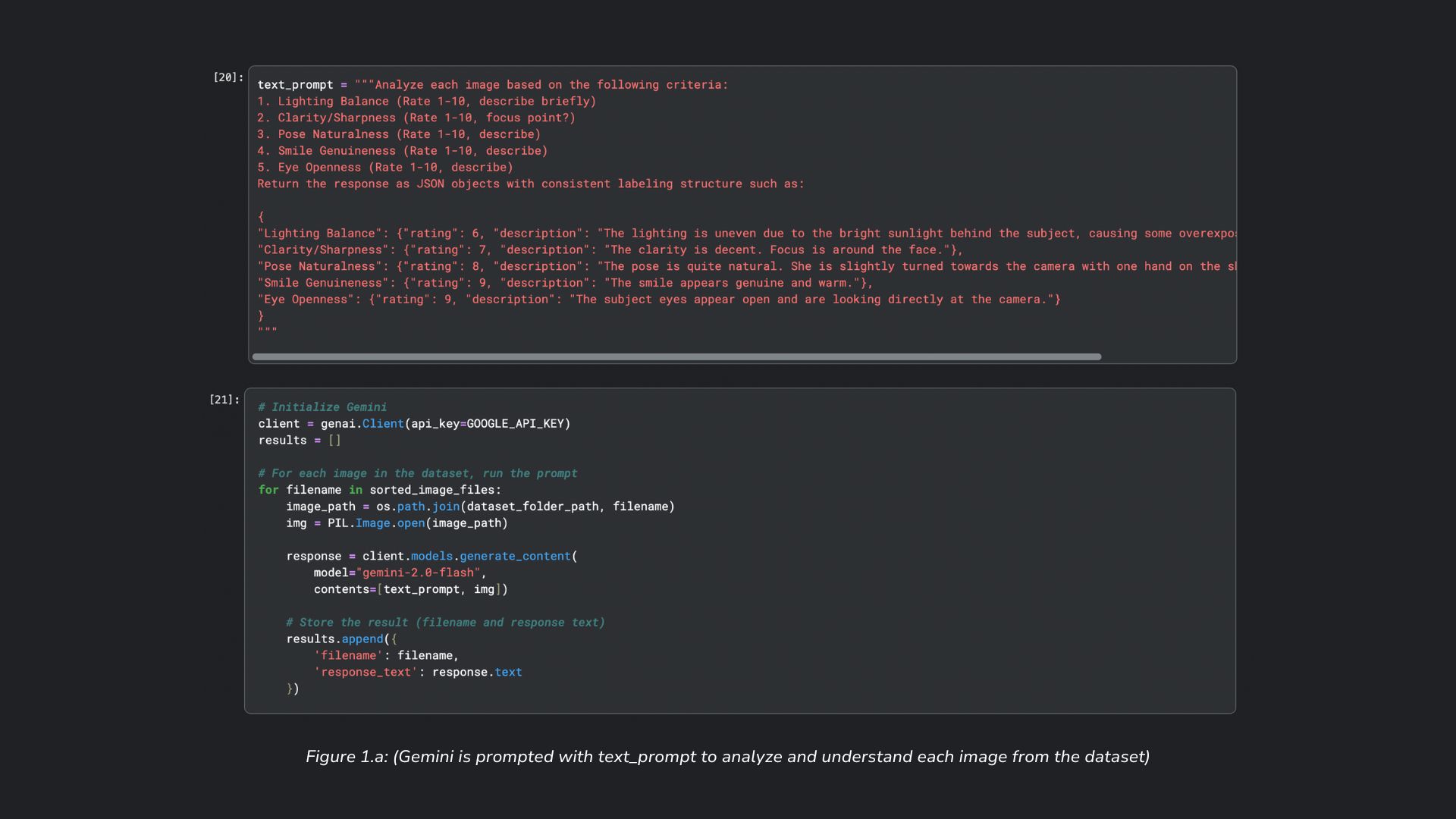
- Employ Image Understanding with Structured output to score each image based on Lighting Balance, Clarity/Sharpness, Pose Naturalness, Smile Genuineness, and Eye Openness
- Further process the images that pass an overall quality threshold, based on an average score of each quality criteria
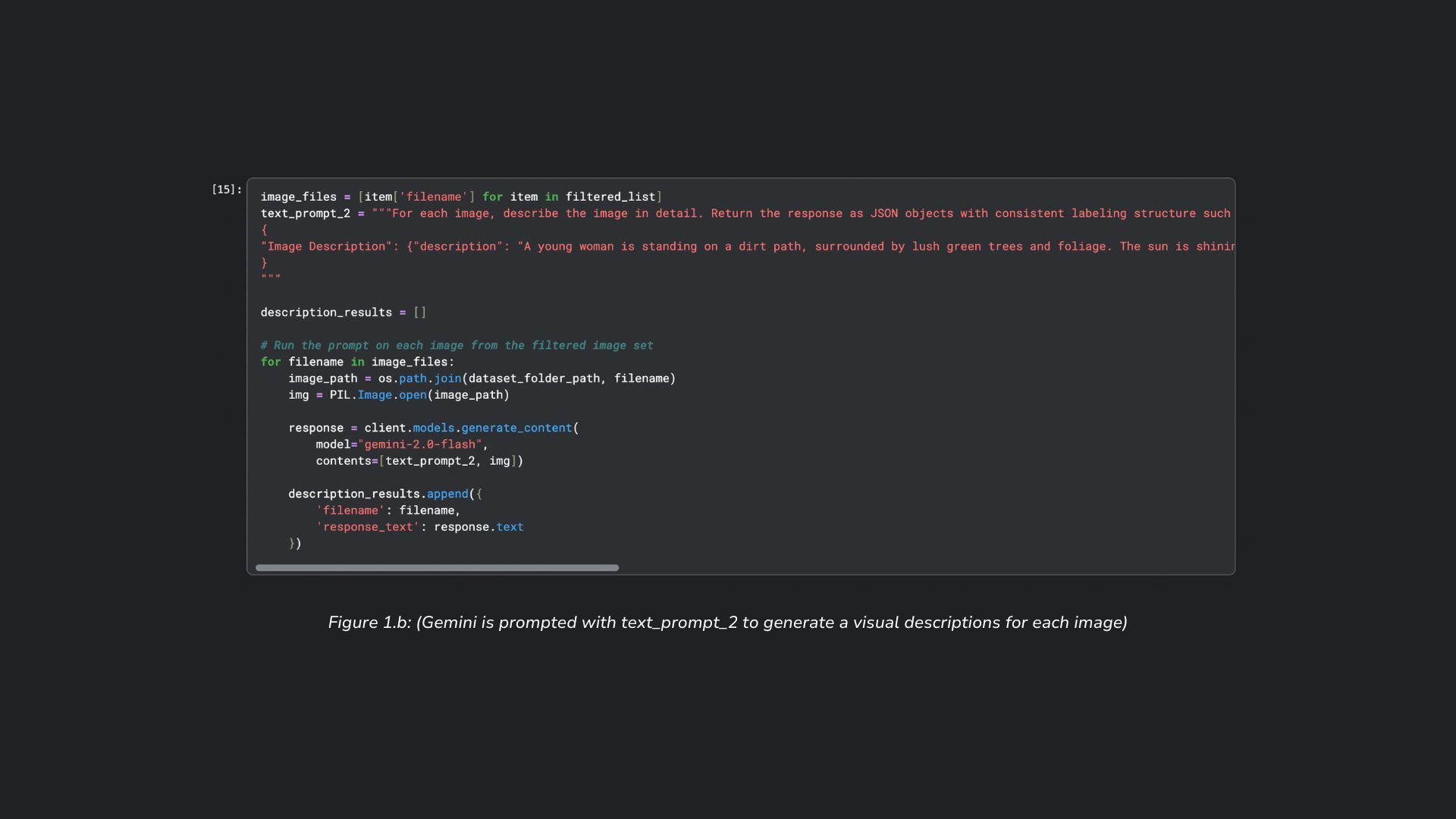
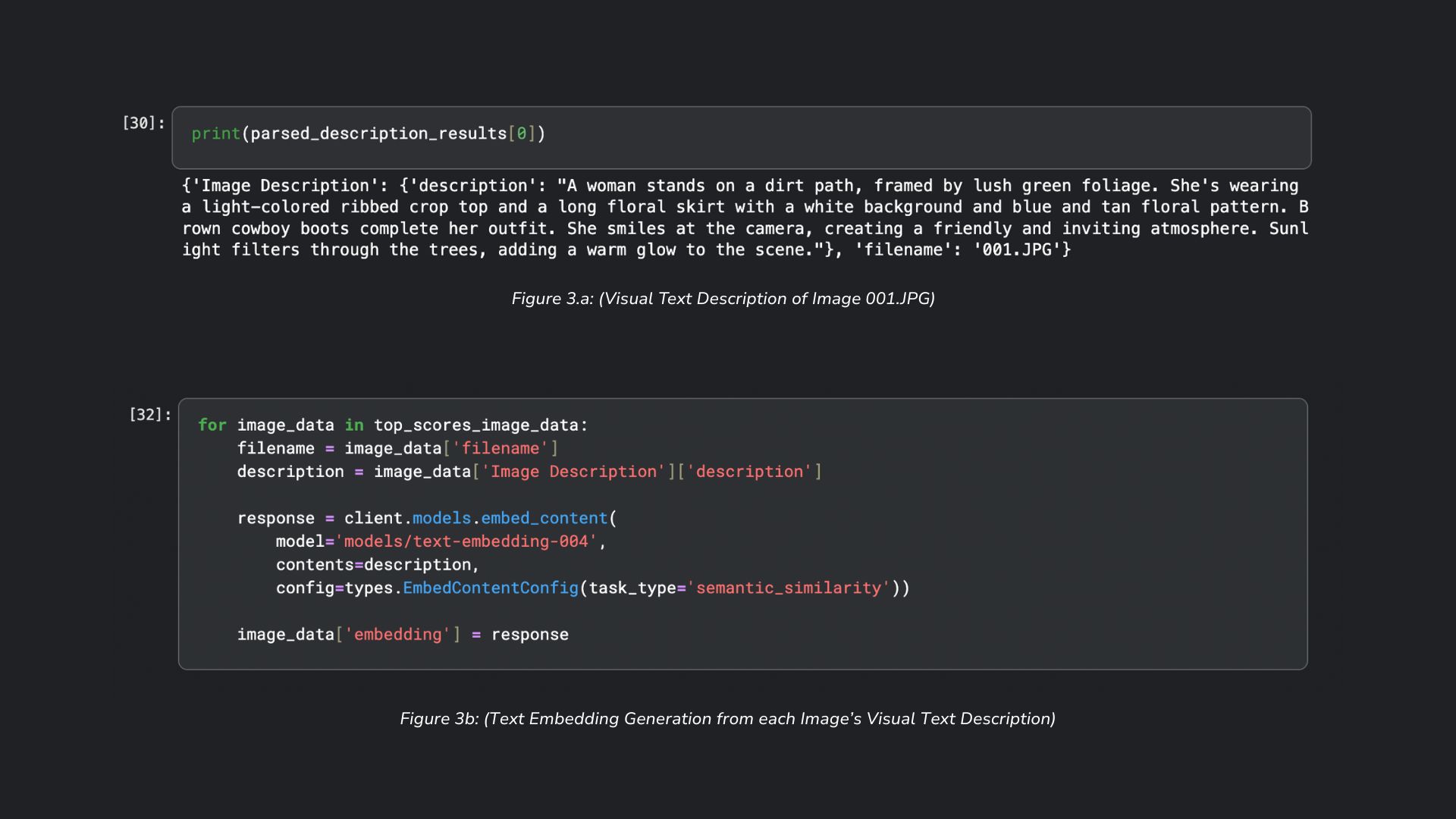
- Generate visual text descriptions using Generative AI as input for Gemini's text embedding model (text-embedding-004)
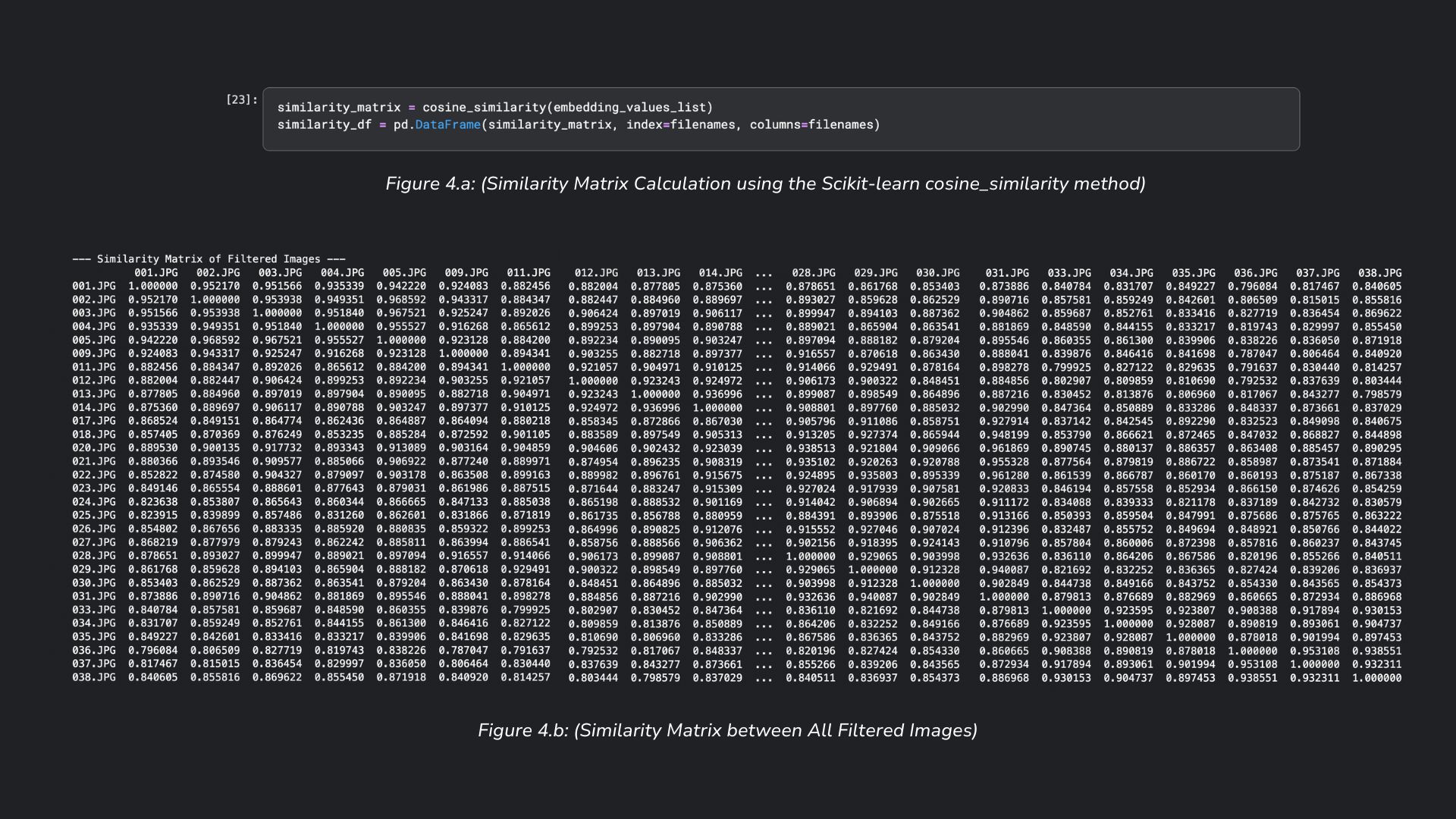
- Create a similarity matrix from the embeddings to greedily select the most unique images from the set of images that meets a quality threshold
Multimodal Embeddings Constraint
I wanted to utilize multimodal embeddings for this project but found that Gemini did not provide a multimodal embedding model. This led me to experiment with Google Cloud's Vertex AI's multimodal embedding model, however, I found it would be difficult for Vertex AI's capabilites to be "reasonably accessible to all" via the Kaggle Notebook and it would have adverse affects from "mininmal costs". In the future, I would love to further this project using Vertex AI's multimodal embedding model, but to ease complexity in this project, I use text embeddings as a proxy for true image embeddings.
Expected Output
The image set presented below was curated prior to the development of the Image Culling System and thus represents a manual selection process, unaided by AI. These images were chosen based on the same quality metrics integrated into the system: lighting, clarity, poses, smiles, and eye openness. In my assessment, these images exhibit the highest quality across these attributes.

Image Pre-Selection, unaided by AI.
Gen AI Capabilities
The following Generative AI Capabilities can be seen demonstrated throughout the Image Culling System:
Image Understanding
Gemini Flash 2.0's Image Understanding capabilities can be seen repeatedly through the course of this project. First, Image Understanding is used to analyze and score each image based on different quality criteria (Lighting Balance, Clarity/Sharpness, Pose Naturalness, Smile Genuineness, and Eye Openeess) as seen in Figure 1.a below. Second, Image Understanding is also used to generate visual descriptions for each image that passes the quality threshold (Figure 1.b). These visual descriptions will later be used for embeddings.
Structured Output (JSON Mode)
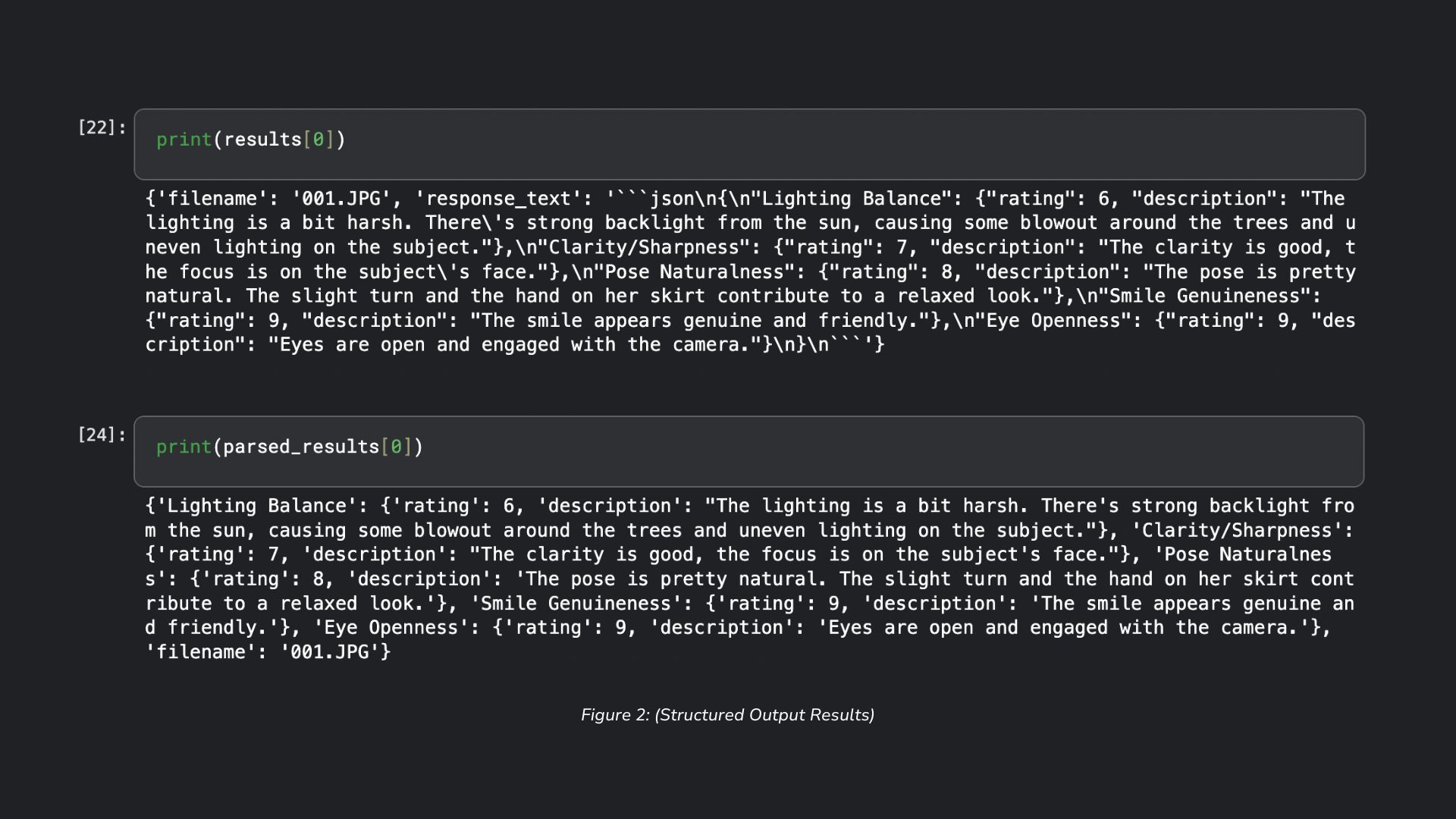
In both Image Understanding instances, where the system receives a response from the model, Structured Output, specifically JSON, is used to enforce a consistent format such that the data collected in the response (i.e. descriptions and scores) can be further processed.
Embeddings
To address the requirement for uniqueness/non-redundancy, text embeddings (numerical vector representations) are generated for each image. As previously mentioned, I wanted this part of my system to use image embeddings via Vertex AI's multimodal embedding model, but insisted on using text embeddings from Gemini's text embedding model for ease of accessibility. While there can be limitations in the visual descriptions of each image, the text embeddings embody the essence of each image, allowing for quantitative measurement of similarity between them.
Vector Search
In Figure 4.a, the cosine similarities are computed for each image, against every other image in the filtered set. A similarity of 1.0 between two images indicates similar images, whereas a similarity score closer to 0.0 indicates less similar images. The similarity scores generated from the embedding vectors (Figure 4.b) are used to identify image similarity in the image selection algorithm, which greedily selects the sufficiently different image from a sorted list of the highest overall scored images.
Project Findings
The developed Image Culling system successfully selected the top K images based on overall quality and a uniqueness constraint. From an initial set of 38 untouched photographs, the system identified ten images ranked as highest quality and most dissimilar. Notably, a comparison with a prior, non-AI-aided pre-selection revealed a 70% overlap (seven identical images). Among the three images uniquely selected by the AI, one (Figure 5: 034.JPG) was deemed unsuitable for inclusion due to the subject being captured mid-blink. Despite this, the initial performance of the Image Culling System is promising. However, its effectiveness may be influenced by factors such as a higher proportion of irrelevant images or varying stylistic preferences across different photographers.

Figure 5: (Output Results of Gemini Flash 2.0 Image Understanding, Ranked by Overall Score)

Figure 6: (Intersect of Selected Images by Human and by Gemini Flash 2.0)
Future Improvements
Addressing current system limitations and new opportunities for further development:
Inclusion of Few Shot Prompting
To assess Gemini's inherent Image Understanding capabilities, the system was initially evaluated without providing specific examples of high-scoring criteria. The model demonstrated reasonable performance despite the ambiguous nature of the scoring requests for attributes like 'Pose Naturalness' and 'Smile Genuineness.' It is anticipated that the system's effectiveness could be significantly enhanced by employing few-shot prompting with illustrative examples prior to scoring requests.
Immediate Removal of Edge Case Images
Currently, the system does not automatically filter images with closed eyes or those that are entirely black and white. While the initial dataset contained few such edge cases, an image of the subject mid-blink was present in the selected set. Enhancing the system to immediately remove these unnecessary images would improve its efficiency and accuracy prior to further processing and scoring.
Calculating Quality Score
At the moment, the system assigns equal weight to each image quality criterion (Lighting Balance, Clarity/Sharpness, Pose Naturalness, Smile Genuineness, and Eye Openness) when calculating overall quality scores. Adjusting these weights to reflect the relative importance of each criterion, such as prioritizing Clarity/Sharpness over Lighting Balance, could lead to a more refined and accurate output.
Last Updated: April 20th, 2025.